Almost a century ago, the discovery of antibiotics like penicillin revolutionized medicine by harnessing the natural bacteria-killing abilities of microbes. Today, a new study co-led by researchers at the Perelman School of Medicine at the University of Pennsylvania suggests that natural-product antibiotic discovery is about to accelerate into a new era, powered by artificial intelligence (AI).
The study, published in Cell, the researchers used a form of AI called machine learning to search for antibiotics in a vast dataset containing the recorded genomes of tens of thousands of bacteria and other primitive organisms. This unprecedented effort yielded nearly one million potential antibiotic compounds, with dozens showing promising activity in initial tests against disease-causing bacteria.
“AI in antibiotic discovery is now a reality and has significantly accelerated our ability to discover new candidate drugs. What once took years can now be achieved in hours using computers” said study co-senior author César de la Fuente, PhD, a Presidential Assistant Professor in Psychiatry, Microbiology, Chemistry, Chemical and Biomolecular Engineering, and Bioengineering.
Nature has always been a good place to look for new medicines, especially antibiotics. Bacteria, ubiquitous on our planet, have evolved numerous antibacterial defenses, often in the form of short proteins (“peptides”) that can disrupt bacterial cell membranes and other critical structures. While the discovery of penicillin and other natural-product-derived antibiotics revolutionized medicine, the growing threat of antibiotic resistance has underscored the urgent need for new antimicrobial compounds.
In recent years, de la Fuente and colleagues have pioneered AI-powered searches for antimicrobials. They have identified preclinical candidates in the genomes of contemporary humans, extinct Neanderthals and Denisovans, woolly mammoths, and hundreds of other organisms. One of the lab’s primary goals is to mine the world’s biological information for useful molecules, including antibiotics.
The first few waves of COVID-19 slowed life across the United States, affecting everything from attending school to eating out for dinner and going on vacation. Segments of health care were also affected: Services that were not considered immediately crucial to fighting the virus were slowed or stopped during the pandemic’s first wave.
But once Penn Medicine invited patients back to resume normal health care—including preventive care, like screenings for disease—there was some lag in numbers.
“As we opened up to routine outpatient care, screening rates for situations when patients didn’t have symptoms were not returning back to normal,” said Mitchell Schnall, MD, PhD, FACR, a professor of Radiology, now the senior vice president for Data and Technology Solutions at Penn Medicine, and then the head of a team focused on the “resurgence” efforts to ease patients back into outpatient care. “Although a short delay in health screening is likely not going to cause long-term health problems, we were concerned whether screening rates would stay lower and lead to a long-term impact.”
Top: Axons in female and male subject brains Bottom: damaged axons in male and female brains after injury (Credit: Penn Medicine)
Important brain structures that are key for signaling in the brain are narrower and less dense in females, and more likely to be damaged by brain injuries, such as concussion. Long-term cognitive deficits occur when the signals between brain structures weaken due to the injury. The structural differences in male and female brains might explain why females are more prone to concussions and experience longer recovery from the injury than their male counterparts, according to a preclinical study led by the Perelman School of Medicine at the University of Pennsylvania, published this week in Acta Neuropathologica.
Each year, approximately 50 million individuals worldwide suffer a concussion, also referred to as mild traumatic brain injury (TBI). However, there is nothing “mild” about this condition for the more than 15 percent of individuals who suffer persisting cognitive dysfunction, which includes difficulty concentrating, learning and remembering new information, and making decisions.
Although males make up the majority of emergency department visits for concussion, this has been primarily attributed to their greater exposure to activities with a risk of head impacts compared to females. In contrast, it has recently been observed that female athletes have a higher rate of concussion and appear to have worse outcomes than their male counterparts participating in the same sport.
“Clinicians have observed for a long time that females suffer from concussion at higher rates than males in the same sports, and that they take longer to recover cognitive function, but couldn’t explain the underlying mechanisms of this phenomenon,” said senior author Douglas Smith, MD, a professor of Neurosurgery and director of Penn’s Center for Brain Injury and Repair. “The variances in brain structures of females and males not only illuminate why this disparity exists, but also exposes biomarkers, such as axon protein fragments, that can be measured in the blood to determine injury severity, monitor recovery, and eventually help identify and develop treatments that help patients repair these damaged structures and restore cognitive function.”
The growing threat of antimicrobial resistance demands innovative solutions in drug discovery. Scientists are turning to artificial intelligence (AI) and machine learning (ML) to accelerate the discovery and development of antimicrobial peptides (AMPs). These short strings of amino acids are promising for combating bacterial infections, yet transitioning them into clinical use has been challenging. Leveraging novel AI-driven models, researchers aim to overcome these obstacles, heralding a new era in antimicrobial therapy.
A new article in Nature Reviews Bioengineering illuminates the promises and challenges of using AI for antibiotic discovery. Cesar de la Fuente, Presidential Assistant Professor in Microbiology and Psychiatry in the Perelman School of Medicine, in Bioengineering and Chemical and Biomolecular Engineering in the School of Engineering and Applied Science, and Adjunct Assistant Professor in Chemistry in the School of Arts and Sciences, collaborated with James J. Collins, Termeer Professor of Medical Engineering and Science at MIT, to provide an introduction to this emerging field, outlining both its current limitations and its massive potential.
In the past five years, groundbreaking work in the de la Fuente Lab has dramatically accelerated the discovery of new antibiotics, reducing the timeline from years to mere hours. AI-driven approaches employed in his laboratory have already yielded numerous preclinical candidates, showcasing the transformative potential of AI in antimicrobial research and offering new potential solutions against currently untreatable infections.
Recent advancements in AI and ML are revolutionizing drug discovery by enabling the precise prediction of biomolecular properties and structures. By training ML models on high-quality datasets, researchers can accurately forecast the efficacy, toxicity and other crucial attributes of novel peptides. This predictive power expedites the screening process, identifying promising candidates for further evaluation in a fraction of the time required by conventional methods.
Traditional approaches to AMP development have encountered hurdles such as toxicity and poor stability. AI models help overcome these challenges by designing peptides with enhanced properties, improving stability, efficacy and safety profiles, and fast-tracking the peptides’ clinical application.
While AI-driven drug discovery has made significant strides, challenges remain. The availability of high-quality data is a critical bottleneck, necessitating collaborative efforts to curate comprehensive datasets to train ML models. Furthermore, ensuring the interpretability and transparency of AI-generated results is essential for fostering trust and wider adoption in clinical settings. However, the future is promising, with AI set to revolutionize antimicrobial therapy development and address drug resistance.
Integrating AI and ML into antimicrobial peptide development marks a paradigm shift in drug discovery. By harnessing these cutting-edge technologies, researchers can address longstanding challenges and accelerate the discovery of novel antimicrobial therapies. Continuous innovation in AI-driven approaches is likely to spearhead a new era of precision medicine, augmenting our arsenal against infectious diseases.
The de la Fuente Lab uses use the power of machines to accelerate discoveries in biology and medicine. The lab’s current projects include using AI for antibiotic discovery, molecular de-extinction, reprogramming venom-derived peptides to discover new antibiotics, and developing low-cost diagnostics for bacterial and viral infections. Read more posts featuring de la Fuente’s work in the BE Blog.
Patients being treated for B-cell non-Hodgkin’s Lymphoma (NHL) who are part of minority populations may not have equal access to cutting-edge CAR T cell therapies, according to a new analysis led by researchers from the Perelman School of Medicine and published in NEJM Evidence.
CAR T cell therapy is a personalized form of cancer therapy that was pioneered at Penn Medicine and has brought hope to thousands of patients who had otherwise run out of treatment options. Six different CAR T cell therapies have been approved since 2017 for a variety of blood cancers, including B-cell NHL that has relapsed or stopped responding to treatment. Image: iStock/PeopleImages
“CAR T cell therapy represents a major leap forward for blood cancer treatment, with many patients living longer than ever before, but its true promise can only be realized if every patient in need has access to these therapies,” says lead author Guido Ghilardi, a postdoctoral fellow in the laboratory of senior author Marco Ruella, an assistant professor of hematology-oncology and scientific director of the Lymphoma Program. “From the scientific perspective, we’re constantly working in the laboratory to make CAR T cell therapy work better, but we also want to make sure that when a groundbreaking treatment like this becomes available, it reaches all patients who might be able to benefit.”
Illustration of the 55LCC complex. (Image: Courtesy of Cameron Baines/Phospho Biomedical Animation)
When cells in the human body divide, they must first make accurate copies of their DNA. The DNA replication exercise is one of the most important processes in all living organisms and is fraught with risks of mutation, which can lead to cell death or cancer. Now, findings from biologists from the Perelman School of Medicine and from the University of Leeds have identified a multiprotein “machine” in cells that helps govern the pausing or stopping of DNA replication to ensure its smooth progress. Illustration of the 55LCC complex. (Image: Courtesy of Cameron Baines/Phospho Biomedical Animation)
The discovery, published in Cell, advances the understanding of DNA replication, helps explain a puzzling set of genetic diseases, and could inform the development of future treatments for neurologic and developmental disorders.
“We’ve found what appears to be a critical quality-control mechanism in cells,” says senior co-corresponding author Roger Greenberg, the J. Samuel Staub, M.D. Professor in the department of Cancer Biology, director of the Penn Center for Genome Integrity, and director of basic science at the Basser Center for BRCA at Penn Medicine. “Trillions of cells in our body divide every single day, and this requires accurate replication of our genomes. Our work describes a new mechanism that regulates protein stability in replicating DNA. We now know a bit more about an important step in this complex biological process.”
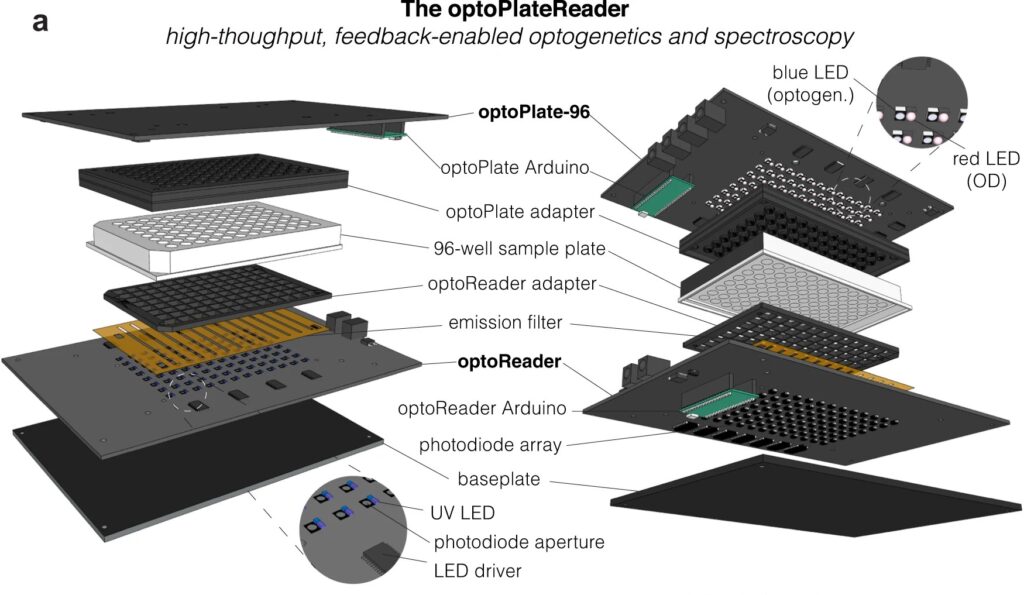
Diagram of the optoPlateReader, a high-throughput, feedback-enabled optogenetics and spectroscopy device initially developed by Penn 2021 iGEM team.
For bioengineers today, light does more than illuminate microscopes. Stimulating cells with light waves, a field known as optogenetics, has opened new doors to understanding the molecular activity within cells, with potential applications in drug discovery and more.
Thanks to recent advances in optogenetic technology, much of which is cheap and open-source, more researchers than ever before can construct arrays capable of running multiple experiments at once, using different wavelengths of light. Computing languages like Python allow researchers to manipulate light sources and precisely control what happens in the many “wells” containing cells in a typical optogenetic experiment.
However, researchers have struggled to simultaneously gather data on all these experiments in real time. Collecting data manually comes with multiple disadvantages: transferring cells to a microscope may expose them to other, non-experimental sources of light. The time it takes to collect the data also makes it difficult to adjust metabolic conditions quickly and precisely in sample cells.
Now, a team of Penn Engineers has published a paper in Communications Biology, an open access journal in the Nature portfolio, outlining the first low-cost solution to this problem. The paper describes the development of optoPlateReader (or oPR), an open-source device that addresses the need for instrumentation to monitor optogenetic experiments in real time. The oPR could make possible features such as automated reading, writing and feedback in microwell plates for optogenetic experiments.
Left to right: Will Benman, Gloria Lee, Saachi Datta, Juliette Hooper, Grace Qian, David Gonzalez-Martinez, and Lukasz Bugaj (with Max).
The paper follows up on the award-winning work of six University of Pennsylvania alumni — Saachi Datta, M.D. Candidate at Stanford School of Medicine; Juliette Hooper, Programmer Analyst in Penn’s Perelman School of Medicine; Gabrielle Leavitt, M.D. Candidate at Temple University; Gloria Lee, graduate student at Oxford University; Grace Qian, Drug Excipient and Residual Analysis Research Co-op at GSK; and Lana Salloum, M.D. Candidate at Albert Einstein College of Medicine — who claimed multiple prizes at the 2021 International Genetically Engineered Machine Competition (iGEM) as Penn undergraduates.
The International Genetically Engineered Machine Competition (or iGEM) is the largest synthetic biology community and the premiere synthetic biology competition for both university and high school students from around the world. Hundreds of interdisciplinary teams of students compete annually, combining molecular biology techniques and engineering concepts to create novel biological systems and compete for prizes and awards through oral presentations and poster sessions.
The optoPlateReader was initially developed by Penn’s 2021 iGEM team, combining a light-stimulation device with a plate reader. At the iGEM competition, the invention took home Best Foundational Advance (best in track), Best Hardware (best from all undergraduate teams), and Best Presentation (best from all undergraduate teams), as well as a Gold Medal Distinction and inclusion in the Top 10 Overall and Top 10 Websites lists. (Read more about the 2021 iGEM team on the BE Blog.)
The original iGEM project focused on the design, construction, and testing of the hardware and software that make up the oPR, the focus of the new paper. After iGEM concluded, the team showed that the oPR could be used with real biological samples, such as cultures of bacteria. This work demonstrated that the oPR could be applied to real research questions, a necessary precursor to publication, and that the device could simultaneously monitor and manipulate living samples.
The main application for the oPR is in metabolic production (such as the creation of pharmaceuticals and bio-fuels). The oPR is able to issue commands to cells via light but can also take live readings about their current state. In the oPR, certain colors of light cause cells to carry out different tasks, and optical measurements give information on growth rates and protein production rates.
In this way, the new device is able to support production processes that can adapt in real time to what cells need, altering their behavior to maximize yield. For example, if an experiment produces a product that is toxic to cells, the oPR could instruct those cells to “turn on” only when the population of cells is dense and “turn off” when the concentration of that product becomes toxic and the cellular population needs to recover. This ability to pivot in real time could assist industries that rely on bioproduction.
The main challenges in developing this device were in incorporating the many light emitting diodes (LEDs) and sensors into a tiny space, as well as insulating the sensors from the nearby LEDs to ensure that the measured light came from the sample and not from the instrument itself. The team also had to create software that could coordinate the function of nearly 100 different sets of LEDs and sensors. Going forward, the team hopes to spread the word about the open-source oPR to other researchers studying metabolic production to enable more efficient research.
Lukasz Bugaj, Assistant Professor in Bioengineering and senior author of the paper, served as the team’s mentor along with Brian Chow, formerly an Associate Professor in Bioengineering and a founding member of the iGEM program at MIT, and Jose Avalos, Associate Professor of Chemical and Biological Engineering at Princeton University.
Key to the project’s development was the guidance of Bioengineering graduate students Will Benman, David Gonzalez Martinez, and Gabrielle Ho, as well as that of Saurabh Malani, a graduate student at Princeton University.
Visualization of a CAR T cell (in red) attacking a cancer cell (in blue) (Meletios Varras via Getty Images)
For patients with certain types of cancer, CAR T cell therapy has been nothing short of life changing. Developed in part by Carl June, Richard W. Vague Professor at Penn Medicine, and approved by the Food and Drug Administration (FDA) in 2017, CAR T cell therapy mobilizes patients’ own immune systems to fight lymphoma and leukemia, among other cancers.
However, the process for manufacturing CAR T cells themselves is time-consuming and costly, requiring multiple steps across days. The state of the art involves extracting patients’ T cells, then activating them with tiny magnetic beads, before giving the T cells genetic instructions to make chimeric antigen receptors (CARs), the specialized receptors that help T cells eliminate cancer cells.
Now, Penn Engineers have developed a novel method for manufacturing CAR T cells, one that takes just 24 hours and requires only one step, thanks to the use of lipid nanoparticles (LNPs), the potent delivery vehicles that played a critical role in the Moderna and Pfizer-BioNTech COVID-19 vaccines.
In a new paper in Advanced Materials, Michael J. Mitchell, Associate Professor in Bioengineering, describes the creation of “activating lipid nanoparticles” (aLNPs), which can activate T cells and deliver the genetic instructions for CARs in a single step, greatly simplifying the CAR T cell manufacturing process. “We wanted to combine these two extremely promising areas of research,” says Ann Metzloff, a doctoral student in Bioengineering and NSF Graduate Research Fellow in the Mitchell lab and the paper’s lead author. “How could we apply lipid nanoparticles to CAR T cell therapy?”
Penn Engineers have developed a way to target lung diseases, including lung cancer, with lipid nanoparticles (LNPs). (wildpixel via Getty Images)
Penn Engineers have developed a new means of targeting the lungs with lipid nanoparticles (LNPs), the miniscule capsules used by the Moderna and Pfizer-BioNTech COVID-19 vaccines to deliver mRNA, opening the door to novel treatments for pulmonary diseases like cystic fibrosis.
In a paper in Nature Communications, Michael J. Mitchell, Associate Professor in the Department of Bioengineering, demonstrates a new method for efficiently determining which LNPs are likely to bind to the lungs, rather than the liver. “The way the liver is designed,” says Mitchell, “LNPs tend to filter into hepatic cells, and struggle to arrive anywhere else. Being able to target the lungs is potentially life-changing for someone with lung cancer or cystic fibrosis.”
Previous studies have shown that cationic lipids — lipids that are positively charged — are more likely to successfully deliver their contents to lung tissue. “However, the commercial cationic lipids are usually highly positively charged and toxic,” says Lulu Xue, a postdoctoral fellow in the Mitchell Lab and the paper’s first author. Since cell membranes are negatively charged, lipids with too strong a positive charge can literally rip apart target cells.
Typically, it would require hundreds of mice to individually test the members of a “library” of LNPs — chemical variants with different structures and properties — to find one with a low charge that has a higher likelihood of delivering a medicinal payload to the lungs.
Instead, Xue, Mitchell and their collaborators used what is known as “barcoded DNA” (b-DNA) to tag each LNP with a unique strand of genetic material, so that they could inject a pool of LNPs into just a handful of animal models. Then, once the LNPs had propagated to different organs, the b-DNA could be scanned, like an item at the supermarket, to determine which LNPs wound up in the lungs.
Like space shuttles using booster rockets to breach the atmosphere, lipid nanoparticles (LNPs) equipped with the new molecule more successfully deliver medicinal payloads. (Love Employee via Getty Images)
Inspired by the design of space shuttles, Penn Engineering researchers have invented a new way to synthesize a key component of lipid nanoparticles (LNPs), the revolutionary delivery vehicle for mRNA treatments including the Pfizer-BioNTech and Moderna COVID-19 vaccines, simplifying the manufacture of LNPs while boosting their efficacy at delivering mRNA to cells for medicinal purposes.
In a paper in Nature Communications, Michael J. Mitchell, Associate Professor in the Department of Bioengineering, describes a new way to synthesize ionizable lipidoids, key chemical components of LNPs that help protect and deliver medicinal payloads. For this paper, Mitchell and his co-authors tested delivery of an mRNA drug for treating obesity and gene-editing tools for treating genetic disease.
Previous experiments have shown that lipidoids with branched tails perform better at delivering mRNA to cells, but the methods for creating these molecules are time- and cost-intensive. “We offer a novel construction strategy for rapid and cost-efficient synthesis of these lipidoids,” says Xuexiang Han, a postdoctoral student in the Mitchell Lab and the paper’s co-first author.